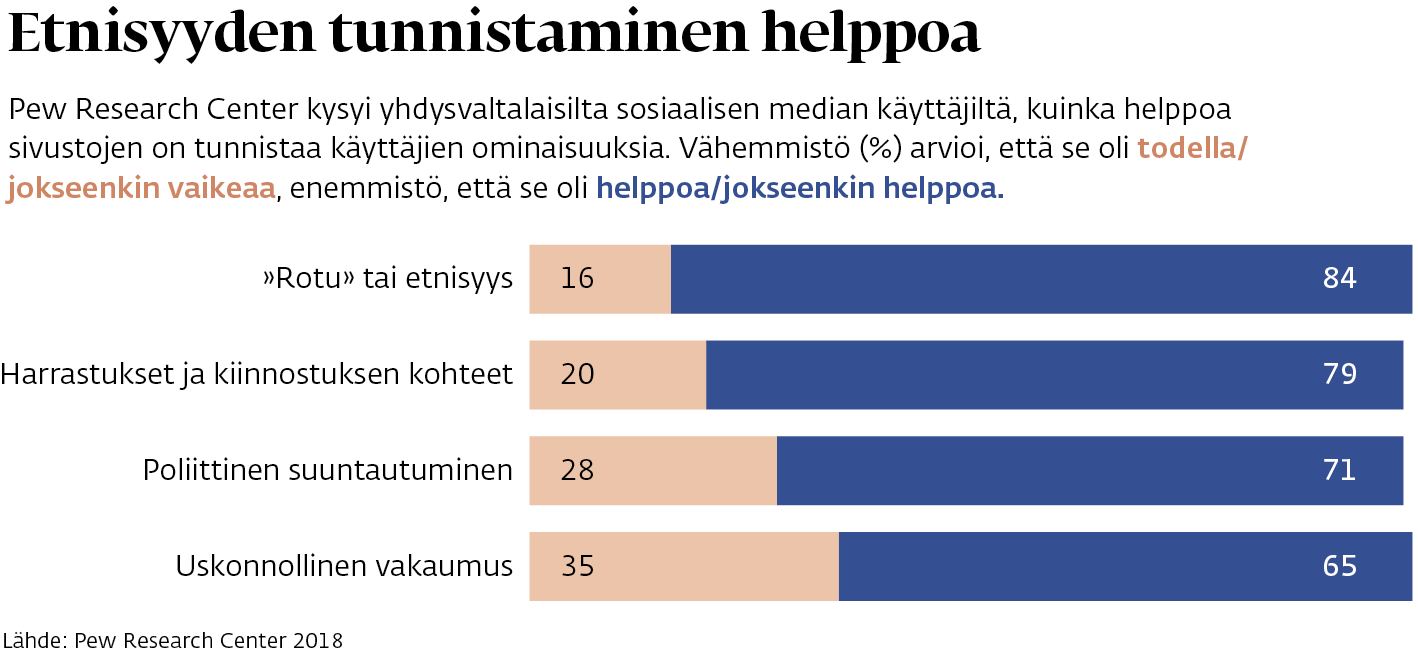
Tekoälyn sääntelystä väännetään globaalisti – algoritmien tekemät tulkinnat tunkevat syvälle yksityisyyteen ja identiteettiin
Tekoälyn sääntelystä väännetään globaalisti – algoritmien tekemät tulkinnat tunkevat syvälle yksityisyyteen ja identiteettiin
Lokakuussa Luxembourgissa toimiva Euroopan unionin tuomioistuin antoi merkittävän ratkaisun: Facebookin pitää poistaa loukkaavaa sisältöä tai vihapuhetta globaalisti, jos jonkin EU-maan tuomioistuin pyytää sitä yhtiöltä.
Ratkaisu liittyi itävaltalaisen vihreän poliitikon Eva Glawischnig-Piesczekin tapaukseen. Eräs Facebookin käyttäjä oli julkaissut palvelussa huhtikuussa vuonna 2016 itävaltalaisen oe24.fi-sivuston artikkelin, jonka otsikko kertoi vihreiden haluavan pitää pakolaisten vähimmäisturvan voimassa.
Facebook-kommentissaan käyttäjä nimitti Glawischnig-Piesczekia »alhaiseksi maanpetturiksi», »korruptoituneeksi typerykseksi» ja »fasistipuolueen» jäseneksi. Facebook-julkaisussa näkyi esikatselukuva oe24.fi-sivustolta, artikkelin otsikko sekä Glawischnig-Piesczekin valokuva.
Glawischnig-Piesczek nosti Facebookia vastaan kanteen, jossa hän vaati yhtiötä poistamaan julkaisut. Unionin tuomioistuin katsoi ratkaisussaan, että EU:n kansalliset tuomioistuimet voivat pyytää Facebookia etsimään ja poistamaan laittomia viestejä alustalta.
»Päätös on esimerkki siitä, kuinka meidän on tasapainoiltava kahden ihmisoikeuden välillä», sanoo Sandra Wachter, Oxfordin yliopiston yhteydessä toimivan Oxford Internet Instituten professori. Ne ovat sananvapaus ja oikeus yksityisyyteen.
Puhelimitse tavoitettu Wachter on kiireinen, sillä juuri nyt hänen tutkimusalansa kiinnostaa ympäri maailman. Hän tutkii tekoälyn ja massadatan etiikkaa lainsäädännön näkökulmasta.
Aihepiiristä on syytä olla kiinnostunut. Joulukuussa 2016 sveitsiläinen Das Magazin paljasti, että Donald Trumpin presidentinvaalikampanja oli hyödyntänyt Cambridge Analytica -nimisen yrityksen keräämää dataa Facebookista. Vuonna 2018 New York Times ja Guardian vahvistivat, että tietoja oli kerätty jopa 50 miljoonan ihmisen Facebook-profiileista.
Tutkimusten mukaan algoritmit vahvistavat niin sanottua kuplautumista. Poliittisen viestinnän kentällä vaikutukset voivat olla dramaattisia: mielipiteet sinkoilevat samanmielisten kaikukammioissa, minkä seurauksena todellisuudet törmäävät keskenään.
Toisaalta algoritmien toiminta ulottuu myös yhä useammin yksilöiden yksityiselämään. EU:n yleisessä tietosuoja-asetuksessa (GDPR) säädetään, että yksilöllä on oikeus tulla unohdetuksi – eli oikeus pyytää tietyissä tilanteissa rekisterinpitäjää poistamaan omia henkilötietoja. Silloin oikeus yksityisyyteen on tärkeämpi arvo kuin oikeus päästä käsiksi tietoihin.
Juuri nyt sananvapauden ja yksityisyyden välillä on ristivetoa eikä sopivaa välimuotoa ole yksinkertaista löytää: »Kumpikin ihmisoikeus on perustavanlaatuinen ja olennainen demokratialle», Wachter sanoo.
Viime syyskuussa Google sai erävoiton. Euroopan unionin tuomioistuin linjasi, että yhtiön ei tarvitse globaalisti soveltaa oikeutta tulla unohdetuksi. Jatkossa Googlen pitäisi poistaa perustellusta pyynnöstä henkilötiedot vain Euroopassa.
Googlen kaltaiset suuryritykset eivät ole innoissaan sääntelyn muodoista, joita EU:ssa on pantu vireille. Euroopassa vaalitaan paitsi sananvapautta ja yksityisyyttä, myös yksilön itsemääräämisoikeutta omaan dataan. Kalifornian Piilaksossa asioita tehdään bisnes edellä. Monet yritykset katsovat, että sääntely tappaa innovaatiot – ja raha ratkaisee.
Applen kätevä Facetime ei ole yhtä ruuhkainen kuin Skype ja toimii siksi paremmin verkkopuhelussa. Sen tietää Turun yliopiston kulttuurihistorian dosentti ja digitaalinen humanisti Asko Nivala, joka vastaa puheluun Yhdysvaltain Bostonissa. Hän on kaupungissa Suomen Akatemian liikkuvuusjaksolla kehittämässä karttoihin ja paikkatietoihin liittyvää tutkimusmetodologiaa.
Nivala on kiinnostunut tekoälyn historiasta, mutta ennen kaikkea hän on 1800-luvun historian tutkija. Tutkimuksessaan hän on perehtynyt myös yksityisen käsitteeseen: vuosisadan alussa oli tavallista, että kirjeitä luettiin ääneen perheen parissa, vaikka ne olivat kahdenvälisiä – niitä saatettiin jopa lainata kolmannelle osapuolelle. Usein naiset hoitivat kirjeenvaihdon.
»Yksityisyyden suoja on 1700-luvun liberalismin perillinen. Kesti kuitenkin kauan ennen kuin yksityisyyden suoja löi kunnolla läpi», Nivala sanoo.
Jo uskonpuhdistus muutti ihmisten käsityksiä yksityisyydestä. Silloin syntyi ajatus siitä, että jokaisella ihmisellä on henkilökohtainen uskonnollinen vakaumus, jonka saattoi yhdistää poliittiseen vakaumukseen. Kukaan ei enää ollut tilivelvollinen julkiselle vallalle omasta uskonnostaan.
Keskiajalla ja esimodernilla ajalla ihmiset eivät välttämättä tehneet suurta eroa oman sisäisen maailmansa ja ulkomaailman välillä. Maalaustaiteen keskeisperspektiivi syntyi renessanssin aikana: silloin maailmaa alettiin kuvata yksittäisen katsojan näkökulmasta. Yksityisyyskäsityksen syntyyn tarvittiin moderni subjekti, yksilö, jolla on rikas sisäinen maailma. Ajatus radikalisoitui valistuksen aikana, ja yksilölle vaadittiin myös poliittisia oikeuksia.
Konkreettisesti filosofi John Locken ajatukset pantiin Yhdysvaltain perustuslakiin. »Jokaisen ihmisen luovuttamattomia oikeuksia käytettiin julistuksen muotoilussa, vaikka orjuus oli käytössä», Nivala sanoo.
Oikeutta yksityisyyteen määrittää perustuslain neljäs lisäys, jonka tulkinta aiheuttaa digiajalla päänvaivaa. Fourth Amendment rajoittaa ennen kaikkea sitä, että viranomaiset eivät saa tehdä kohtuuttomia henkilötarkastuksia tai kotietsintöjä. Sen perimmäinen tarkoitus on suojella yksilöä valtiolta.
Kesäkuussa 2018 Yhdysvaltain korkein oikeus linjasi, että viranomaisten olisi vastedes hankittava lupa tuomioistuimelta ennen kuin valtio voisi saada haltuunsa yksityishenkilön puhelimen paikkatietoja teleyhtiöiltä.
Carpenter vastaan Yhdysvallat -jutussa oli kyse vuonna 2010 alkaneesta ryöstöjen sarjasta Detroitissa. Rikoskumppaneiden mukaan Timothy Carpenter oli tekojen pääsuunnittelija, minkä lisäksi Carpenterin puhelimen paikkatiedot yhdistivät hänet rikospaikkoihin.
Teleyhtiöt olivat luovuttaneet 127 päivän ajalta dataa, jonka avulla Carpenterin puhelin paikallistettiin 12 898:aan sijaintiin. Niin massiivinen kurkistus yksilön liikkeisiin oli oikeuden termein kaiken kattavaa.
Carpenter joutui teoista vankilaan, mutta korkein oikeus katsoi, että paikkatietojen kerääminen ilman lupaa loukkasi Carpenterin perustuslain neljännessä lisäyksessä säädettäviä oikeuksia.
»Lisäyksen perimmäinen tarkoitus on turvata yksilön yksityisyys ja turvallisuus valtion virkamiesten tekemiltä sattumanvaraisilta yksityisyyden loukkauksilta», todetaan myös Carpenter-ratkaisussa.
Nivala huomauttaa, että julkinen ja yksityinen ovat suhdekäsitteitä, jotka määrittyvät toistensa kautta. Julkisella tarkoitetaan usein valtioita, yksityisellä yrityksiä. Digitaalinen kulttuuri on monimutkaistanut tätä suhdetta.
»Historiallisesti tiedämme, että kansallissosialistinen Saksa ja Neuvostoliitto vakoilivat kansalaisiaan ja keräsivät heistä tietoa, joka loukkasi yksityisyyden suojaa. Nyt yritykset keräävät käyttäjistä tietoja, joskin käyttäjän suostumuksella», hän sanoo. Vaikka datan kerääminen suostumuksella ei ole rikollista toimintaa, käyttäjät voivat olla naiiveja tai tietämättömiä antaessaan siihen luvan.
Ylen tutkivan journalismin MOT-toimitus kertoi lokakuussa, että joissakin suhteellisen edullisissa Android-puhelimissa on esiasennettuna ulkopuolisten yhtiöiden, kuten Facebookin, Bookingin ja Linkedinin, ohjelmistoja. Silloin käyttäjä joutuu hyväksymään ohjelman jo ottaessaan puhelimen käyttöön eikä voi tutustua käyttöehtoihin samalla tavalla kuin ladatessaan sovelluksen itse.
Nivala pohtii, että valtion sijaan yksilön yksityisyyttä uhkaavat nyt toimijat, jotka tulevat yksityisen maailman sisältä. Keskustelun ytimessä ovat Facebookin ja Googlen kaltaiset teknologiajätit, joiden bisnesmalli perustuu käyttäjien luovuttaman datan kaupalliseen hyödyntämiseen.
Markkina-arvolla laskettuna maailman kymmenestä suurimmasta yrityksestä seitsemän on teknologiajättejä. Googlen emoyhtiö Alphabet on listalla neljäntenä Applen, Microsoftin ja Amazonin jälkeen, Facebook kuudentena.
Yksityisyyden suoja on 1700-luvun liberalismin perillinen.
Helsingin Wanhassa satamassa käteen saa tarran: oletko aloittelija vai konkari? Tarralla voi viestiä lähtötasonsa ja valmistautua verkostoitumaan. Ruokaa ja juomaa on tarjolla, vapaalle keskustelulle on varattu oma alueensa käytävän päästä.
Käynnissä on kaksipäiväinen My Data 2019 -konferenssi, jonka osallistujalistalla on ihmisiä niin Microsoftin, Valtiokonttorin, erilaisten teknologia-startupien kuin suurlähetystöjenkin riveistä. Konferenssin järjestäjällä My Data Globalilla on tavoite: »voimauttaa yksilöitä parantamalla heidän oikeuksiaan päättää itse omasta datastaan», kuten järjestön verkkosivuilla muotoillaan.
Lehdistötilaisuudessa Meeco-nimisen yrityksen perustaja Katryna Dow esittää näkemyksensä datan omistajuuden tulevaisuudesta. Meeco on kehittänyt sovelluksen yksilön oman datan hallintaan ja datan käyttöoikeuksien myöntämiseen.
Dow mainitsee kauhukuvana digitaalisen orjuuden. Siinä maailmaan syntyvät vauvat eivät voi muuta kuin sopeutua yhteiskuntaan, jossa ei ole mekanismeja turvalliseen digitaaliseen kansalaisuuteen. Ihmiskunta on vasta heräämässä datan hallintaan, vaikka joitain askeleita on jo otettu, Dow arvioi. Hän selittää, että meillä ei toistaiseksi ole infrastruktuuria modernissa digitaalisessa maailmassa luoviville perheille.
Kauhukuvat juontavat juurensa siihen, että tekoälyn perustana olevien algoritmien toiminta ei ole läpinäkyvää. Ne ovat mustia laatikoita: tekoäly nojaa toiminnassaan suuriin määriin tietoa, mutta ulkopuolisille ei ole selvää, miten koneet saavuttavat päätelmänsä. Yritykset varjelevat algoritmien toiminnan logiikkaa liikesalaisuuksina, vaikka ne tekevät yksilön elämää koskevia tärkeitä päätöksiä.
Perinteisessä tilanteessa olisimme fyysisesti pankissa hakemassa lainaa. Pankinjohtaja kysyisi aiheeseen liittyviä kysymyksiä, kuten sen, kuinka paljon lainanhakija saa vuodessa palkkaa.
Verkossa algoritmi sen sijaan voi toimia eri tavalla: päättäessään lainanottajan kelpoisuudesta se voi käyttää hyväkseen sosiaalisen median dataa, selailuhistoriaa, ostohistoriaa ja niin edelleen, Wachter listaa. »Käyttäjän verkkokäyttäytymistä arvioidaan ja siitä tehdään tulkintoja, eikä käyttäjällä ole hajuakaan siitä, mitä on meneillään.»
Määritelmällisesti algoritmi on luettelo ohjeita, ikään kuin resepti, kuvaa Helsingin yliopiston tietojenkäsittelytieteen apulaisprofessori Teemu Roos. Hän opettaa Helsingin yliopiston ja Reaktorin avoimella Elements of AI -verkkokurssilla. Kurssille on tähän mennessä ilmoittautunut noin 210 000 ihmistä, joista suomalaisia on hieman alle puolet.
Roos sanoo, että tekoäly perustuu automaattisiin järjestelmiin, joita käyttäjän ei tarvitse valvoa. »Sellainen voi olla vaikka robotti Marsissa», hän kuvaa. Toiseksi tekoäly on usein adaptiivista, eli se oppii kokemuksen kautta lisää uusia asioita.
Roosin mukaan algoritmien koodirivit on mahdollista tarkistaa rivi riviltä, sillä joku ihminen on ne kulloinkin koodannut. Toisaalta riittävän pitkälle adaptoituneen algoritmijärjestelmän toimintaa on vaikea ennustaa. Roos sanoo, että kukaan ei voi tietää ennalta, miten adaptiivisen algoritmin ja sen käyttäjien yhteispeli etenee.
Arkikielessä algoritmilla tarkoitetaan usein sosiaalisesta mediasta tuttuja filtterialgoritmeja, jotka datasta oppimalla pyrkivät määrittämään, mikä ihmisiä voisi kiinnostaa – tai mikä saisi käyttäjän pysymään sovelluksen äärellä mahdollisimman pitkään.
Tekoälyn etiikan tutkija Sandra Wachter kiinnostui tutkimuksessaan ensin algoritmien toiminnasta juuri mustien laatikoiden takia: niiden toimintaa ei pystynyt selittämään. Sitten hän havahtui siihen, että algoritmit eivät ole tilivelvollisia kenellekään.
Kollegoidensa Brent Mittelstadtin ja Chris Russellin kanssa Wachter loi ajatuksen vaihtoehtoisista selityksistä eli siitä, minkä ehdon pitäisi muuttua, jotta algoritmin saavuttama lopputulos olisi erilainen. Olisiko algoritmi esimerkiksi sittenkin myöntänyt lainanhakijalle lainan, jos tämä olisi ollut eri sukupuolta?
Vaihtoehtoiset selitykset auttavat ymmärtämään, miksi algoritmi saavutti tietyn lopputuloksen ilman, että mustaa laatikkoa tarvitsee avata. Google otti tutkijoiden ideasta kopin ja toteutti sen käytännössä What-if-sovelluksessaan viime vuonna.
Mutta selityksetkään eivät riitä, korostaa Wachter. Vaikka ymmärtäisimme, miksi algoritmit toimivat tietyllä tavalla, sekään ei lopulta oikeuta niiden toimintaa.
»Oikeasti meidän pitää olla kiinnostuneita selitysten taustalla olevista oletuksista», Wachter sanoo. Silloin keskeisiä ovat tulkinnat.
Sosiaalisesta mediasta saatava data on osoittautunut käteväksi työkaluksi lainanhakijan luottokelpoisuuden arvioinnissa. Talouslehti Financial Times kertoi jo vuonna 2016 saksalaisesta Kreditech-yrityksestä, joka pyytää lainanhakijaa jakamaan tiedot tämän sosiaalisen median verkostoista. Yhtiön silloinen talousjohtaja Rene Griemens totesi lehdelle, että näin yritys voi saada tietoa hakijan mahdollisista kavereista, jotka ovat jo maksaneet lainansa takaisin – tieto, joka Griemensin mielestä oli hyvä indikaattori lainakelpoisuudesta.
Yhdysvalloissa keskustelua ovat herättäneet algoritmit, jotka syrjivät lainanhakijoita esimerkiksi sen perusteella, millä postinumeroalueella nämä sattuvat asumaan. Tutkivan journalismin uutismedia Pro Publica kertoi vuonna 2017, että vähemmistöjen asuinalueilla vakuutusyhtiöt laskuttivat autovakuutuksesta enemmän kuin ei-vähemmistöjen asuinalueilla.
Berkeleyn yliopiston tutkijat kuitenkin huomasivat viime keväänä, että algoritmit itse asiassa syrjivät vähemmistöön kuuluvaa lainanhakijaa vähemmän kuin lainoja myöntävät ihmiset kasvokkain tapahtuvissa lainanhakutilanteissa.
Suomessa Osuuspankissa, Nordeassa ja Danske Bankissa tekoäly ei pankkien mukaan toistaiseksi tee täysin automatisoituja asuntolainapäätöksiä. Tekoälyä tai robotiikkaa käytetään kuitenkin luottopäätösten apuna Osuuspankissa ja Nordeassa.
Osuuspankilla on vuoden verran ollut käytössä datapohjaiseen analysointiin perustuva digitaalinen asuntolainatarjouspalvelu, johon asiakas syöttää tietoja. »Palvelu perustuu pitkälti tekoälyyn, dataan ja erilaisten matemaattisten ja tilastollisten mallien käyttöön», sanoo OP:n asumisen ja rahoituksen johtaja Kaisu Christie.
OP:n palvelussa analysoidaan asiakkaan maksukykyä, luottotietoja ja ostettavan asuntokohteen arvoa sekä esimerkiksi asuntokohteen alueen profiilia. Asiakkaan kanssa lainasta neuvottelee ja päätöksen tekee kuitenkin pankin toimihenkilö – siis ihminen. Christien mukaan OP:n »luottopäätöskone» ei ota huomioon lainanhakijan sosiaalisesta mediasta saatavaa dataa. Maanmittauslaitokselta ja Suomen Asiakastiedon kautta saatava data tulevat palveluun pankin ulkopuolelta.
On tiedossa, että ihmisen epätäydellisyys siirtyy myös algoritmeihin. »Algoritmit ovat vain niin hyviä kuin data, jota niihin syötetään. Jos data on vanhentunutta, virheellistä, puutteellista tai huonosti valittua, myös tulokset ovat kyseenalaisia», muotoillaan Euroopan unionin perusoikeusviraston FRA:n algoritmien syrjintää käsittelevässä muistiossa vuodelta 2018.
Sandra Wachterin mukaan on olennaista ymmärtää, että algoritmien tekemät tulkinnat tunkevat syvälle yksilön autonomiaan, yksityisyyteen ja identiteettiin. Sitä nykylainsäädäntö ei ota tarpeeksi huomioon. Wachter katsoo, että yksilöllä olisi oikeus tiettyyn pisteeseen saakka kontrolloida, miten hän tulee nähdyksi. Ajatus on samankaltainen kuin oikeus tulla unohdetuksi.
Hän kutsuu sitä »oikeudeksi kohtuullisiin päätelmiin».
Meidän pitää olla kiinnostuneita algoritmien selitysten taustalla olevista oletuksista.
Viime kesänä Euroopan komission puheenjohtajaksi valittu Ursula von der Leyen ilmoitti, että uusi komissio edistää sadan ensimmäisen työpäivänsä aikana kattavaa tekoälylainsäädäntöä. Osa jäsenmaista, Suomi mukaan lukien, jäi ihmetellen odottamaan: kuinka kattava paketti olisi mahdollista kursia kasaan niin lyhyessä ajassa?
Politico-lehden mukaan Saksalla on vahvasti näppinsä pelissä lainsäädännön valmistelussa. Taustalla on Angela Merkelin hallituksen asettaman dataetiikkatyöryhmän raportti, josta uumoillaan pohjapaperia myös EU:n lainsäädännölle. Von der Leyenin edellinen poliittinen virka oli Merkelin hallituksessa puolustusministerinä.
Lehden mukaan saksalainen raportti suosittaa algoritmisten järjestelmien laajaa sääntelyä, joka kattaa sekä yksityiset yritykset että julkiset toimijat. Juuri sitä teknologiajätit lobbareineen ovat pelänneet.
Suomi on yleisesti kannattanut harkintaa uusien teknologioiden sääntelyssä ja toisaalta korostanut yritysten kilpailukyvyn merkitystä. Perusperiaatteena on ennemminkin ollut kuulla eri sektoreiden mielipiteitä kuin kannattaa tekoälyn laajaa ja kattavaa sääntelyä.
Juha Sipilän hallituksen elinkeinoministeri Mika Lintilä (kesk.) aloitti tekoälyohjelman työstämisen vuonna 2017, ja hankkeesta valmistui loppuraportti viime keväänä. Yhtenä toimenpiteenä raportti suosittaa, että datan hyödyntämisen pelisääntöjä selkiytetään »yritysten, yhteiskunnan ja käyttäjien näkökulmasta». Lisäksi se tukee alan itsesääntelyä.
Yksityisyyden vaalimisella on Saksassa pitkät perinteet. Jo vuonna 1983 Saksan valtiosääntötuomioistuin linjasi väestönlaskentaan liittyneessä tapauksessa tietoja koskevasta itsemääräämisoikeudesta (informationelle Selbstbestimmung). Ratkaisun mukaan yksilöllä on pääsääntöisesti oikeus päättää, mitä dataa hänestä luovutetaan ja miten sitä käytetään.
Tämä periaate näkyy myös EU:n yleisessä tietosuoja-asetuksessa, joka astui voimaan keväällä 2018.
»Meille saksalaisille tietoja koskeva itsemääräämisoikeus on tarkempi käsite kuin yksityisyys», sanoo Ingrid Schneider, Hampurin yliopiston informaatioteknologian etiikan professori.
Schneiderin tausta on politiikan tutkimuksessa. Hänen mielestään dataa bisnesmalleissaan hyödyntävät suuret teknologiayhtiöt ovat merkittäviä vallankäyttäjiä. Ne ovat portinvartijoita ja sääntöjen luojia: käyttäjä joko hyväksyy käyttöehdot tai ei voi käyttää palvelua ollenkaan.
Yhtiöt ovat luoneet yksityisen järjestyksen, jonka säännöt ne määrittelevät. »Se ei ole ainoastaan huono asia, mutta kansalaisten, kuluttajien ja näiden yritysten välillä on useita epäsuhtia. Siksi sääntelyä tarvitaan», hän sanoo.
Tietosuoja-asetus GDPR on Schneiderin mielestä loistava työkalu datan sääntelyyn, sillä se toimii esimerkkinä muualla maailmassa. Esimerkiksi Brasilia on panemassa täytäntöön kokonaisvaltaista datan yksityisyyden lainsäädäntöä, ja Yhdysvalloissa vastaava Kalifornian Consumer Privacy Act (CCPA) astuu voimaan ensi vuonna.
Muutoinkin Kalifornia kallistuu sääntelyyn: osavaltio on kieltänyt vuoden 2020 alusta lailla kasvojentunnistusteknologian käytön poliisien vartalokameroissa. Osavaltio on kieltänyt myös poliittisten deepfake-videoiden eli huijaus- ja väärennösvideoiden tekemisen ja levittämisen 60 päivää vaalien alla.
Kiinassa painotus on täysin toinen. Maa testaa parhaillaan eri kaupungeissa sosiaalisen pisteytyksen järjestelmää. Kansalaisille annettavan pisteytyksen mahdollistaisivat muun muassa algoritmit ja kasvojentunnistusteknologia, joita Kiina käyttää kansalaistensa tarkkailuun. Järjestelmässä jokaisella kiinalaisella olisi henkilökohtainen pistemäärä, joka ilmaisee, kuinka luotettava yksilö on yhteiskunnallisesti. Epävarmaa kuitenkin on, milloin järjestelmä tulisi käyttöön koko maassa.

Toistaiseksi Eurooppa on Ingrid Schneiderin mielestä jäänyt amerikkalaisen libertaarin data- ja alustakapitalismin sekä kiinalaisen keskushallintojohtoisen autoritaarisen datahallintajärjestelmän väliin. Silti hän sanoo olevansa optimisti datan globaalin sääntelyn suhteen.
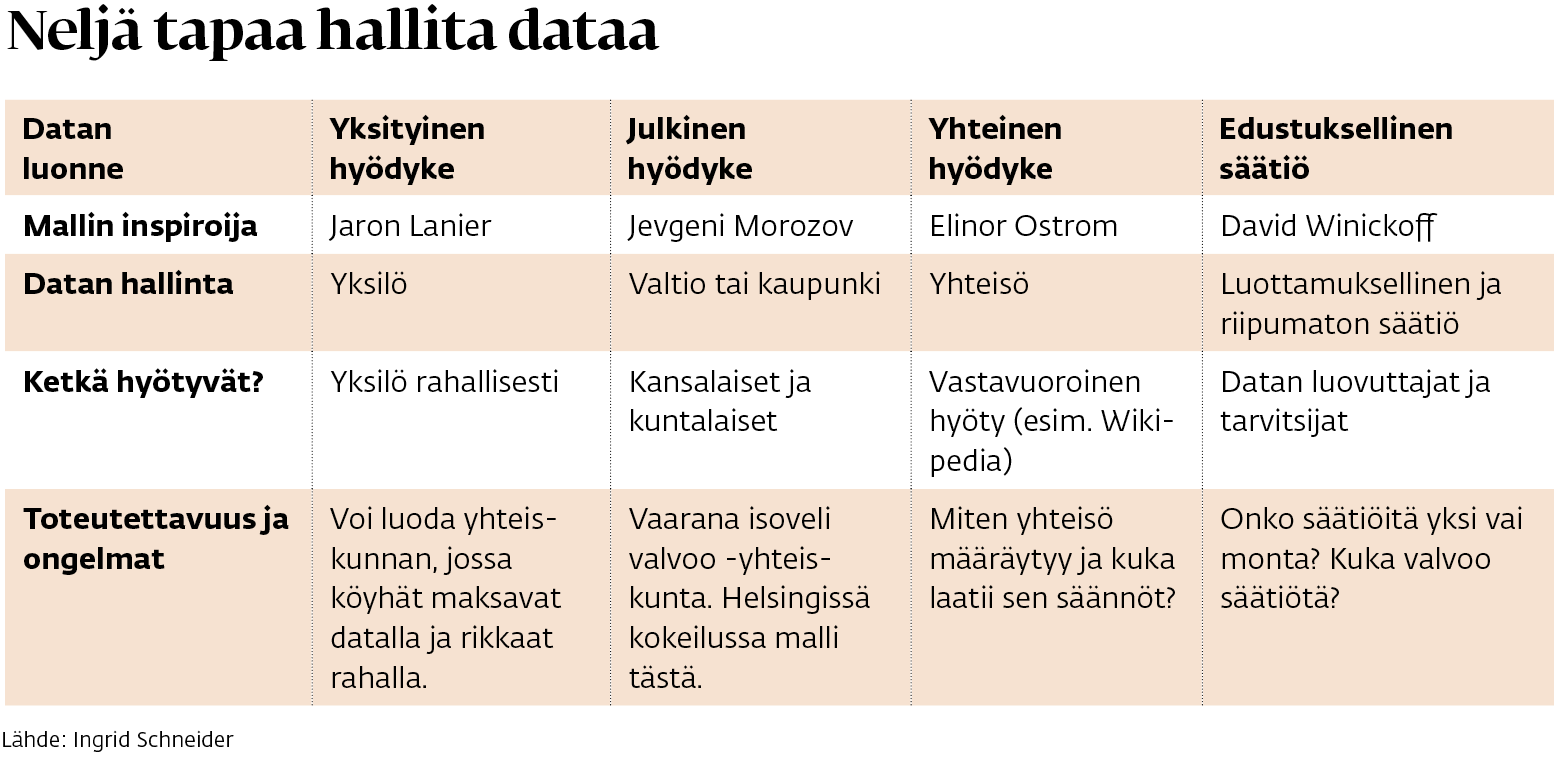
Schneider on kehittänyt neljä teoreettista mallia, joilla dataa voisi tulevaisuudessa hallita. Ensimmäisessä mallissa data toimisi yksityisenä hyödykkeenä, jota yksilö voisi mikromaksuin myydä eteenpäin. Toisin kuin nyt, järjestely tuottaisi taloudellista hyötyä yksilölle, ei vain suurille yhtiöille. Ongelmaksi voisi kuitenkin koitua kahden kerroksen kansalaisuus: rikkaiden ei tarvitsisi myydä dataa, mutta köyhille se olisi välttämätöntä.
Toisessa mallissa data olisi jonkin julkisyhteisön, kuten kaupungin tai kunnan, hallussa. Se käyttäisi dataa alueensa ja toimintojensa kehittämiseen ja voisi luovuttaa datatietoja pienille ja keskisuurille yrityksille. Esteeksi voisi kuitenkin muodostua se, kuinka kattavat oikeudet kaupunki tai kunta saa yksilön dataan.
Kolmannessa mallissa data olisi yleinen hyödyke, jota yhteisöt hallinnoisivat. Silloin dataa jaettaisiin – tai sen käyttöä vastaavasti rajoitettaisiin – yhteisön jäsenten toiveiden mukaan. Päänvaivaa toisi se, kuka saa määrittää, millaisia yhteisöt ovat ja missä niiden rajat kulkevat.
Neljännessä mallissa dataa hallinnoisi riippumaton ja yleishyödyllinen säätiö, jolle yksilö voisi kertoa, mihin tarkoitukseen hänen dataansa saisi käyttää. Yksityishenkilö voisi esimerkiksi kieltää datansa käytön aseiden tuotekehittelyssä tai myöntää käyttöoikeudet lääketieteelliseen tutkimukseen. Mallin ongelmana on se, kuka tai mikä taho valvoisi säätiöiden toimintaa.
Yksikään malli ei välttämättä toimisi sellaisenaan, sillä ne ovat ideaalityyppejä, Schneider sanoo. Todennäköisempi skenaario on yhdistelmä eri malleista.
Ensin tulee kuitenkin ratkaista, mikä taho edustaa datan käyttäjiä ja luovuttajia kollektiivisesti. »Miten järjestämme tämän?» Schneider kysyy.
Tietojenkäsittelytieteen apulaisprofessori Teemu Roos tunnustautuu niin ikään GDPR:n faniksi. Hänestä se on hieno palanen datan hallinnan lainsäädäntöä – juuri sen takia, että se koskee rajatusti henkilötietojen hallintaa.

Roos vastustaa sitä, että tekoälylle luotaisiin oma lainsäädäntökehikkonsa, sellainen kuin vaikka sodankäynnillä on. Hänestä olemassa on jo lainsäädäntöä lähes kaikkeen, mitä tekoälyllä voi tehdä. Eri lakeja pitäisi hänen mielestään nimenomaan päivittää tekoälyaikaan sopiviksi.
Lokakuussa Roos osallistui entisistä presidenteistä ja pääministereistä koostuvan Madridin klubin tekoälyä ja demokratiaa käsittelevään konferenssiin. Siellä annettiin toimenpide-ehdotus poliitikkoja vastaan tehtyjen deepfake-videoiden kriminalisoinnista.
Roosista se oli outoa. Vihapuhe ja väärän tiedon levittäminen ovat väärin, oli tekoälyä tai ei.